در دو مطلب قبلی به چیستی و چرایی دیتا ساینس پرداختم که میتونید در در اینجا به قسمت اول و دوم مجموعه مقالات آشنایی با دیتا ساینس درسترسی داشته باشید. در ادامه مطالب قبلی، در اینجا قصد دارم به بررسی متدلوژی دیتا ساینس (Data Science Methodology) بپردازم. با من همراه باشید.
متدولوژی دیتا ساینس چیست؟ جواب این سوال ساده ست، مجموعه روشهایی که دیتا ساینتیست ها بکار میگیرند تا با استفاده از داده های موجود راه حلی را برای یک مساله مشخص بیابند رو متدولوژی دیتا ساینس می گویند.
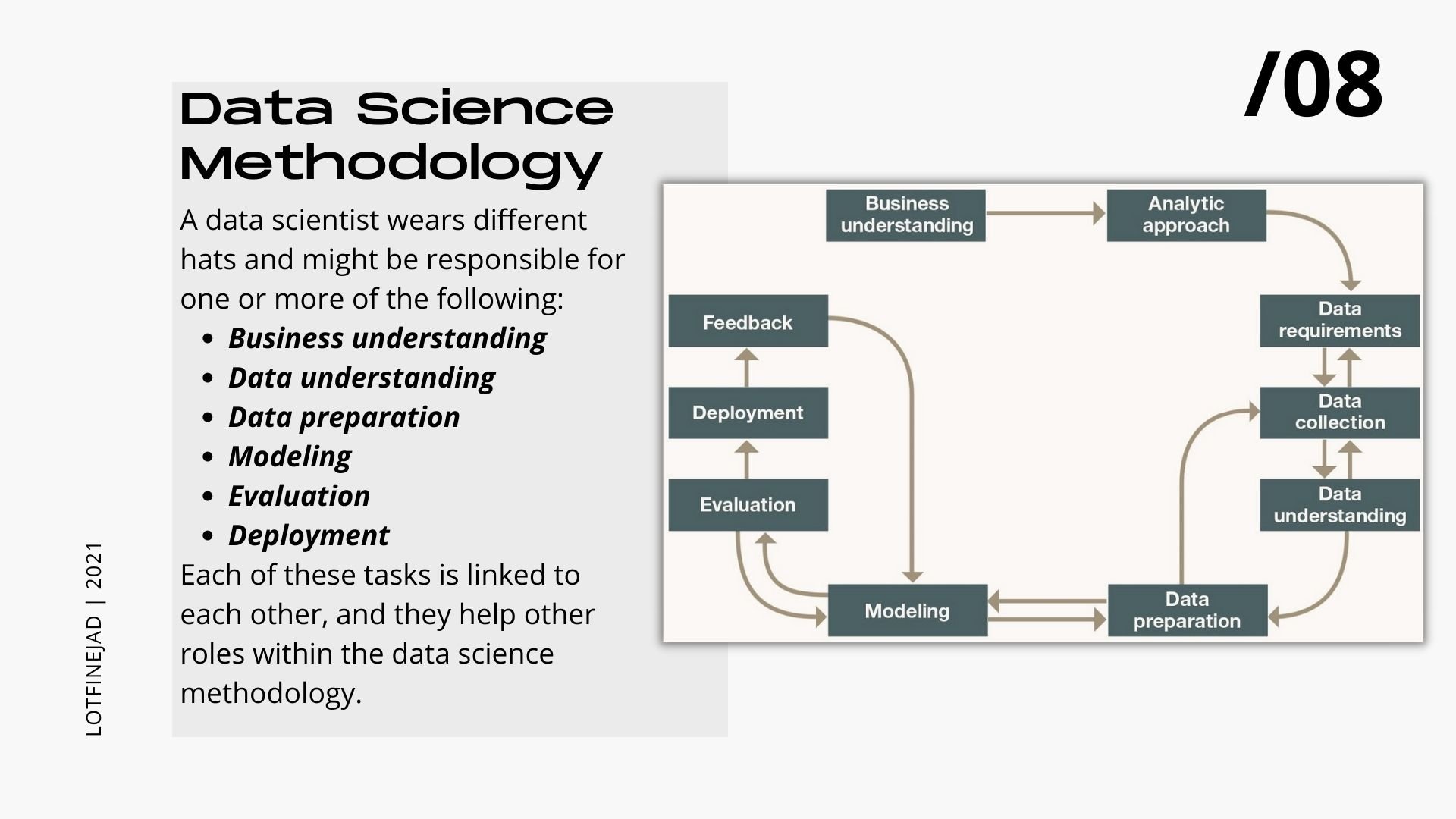
متدولوژی ها زیادی در حوزه دیتا ساینس وجود داره که من در اینجا میخوام به یکی از معروفترین آنها که توسط IBM ارایه شده بپردازم. این متدولوژی از۶ مرحله اصلی و چند مرحله فرعی تشکیل شده که در مجموع به دیتا ساینتیست ها کمک میکنند که سریعتر، راه حلهای قابل اعتماد ارایه دهند.
شناخت مساله و رویکرد حل مساله
در ابتدا باید بدونیم چه مساله ای در کسب و کار رو باید حل کنیم. برای این کار هم باید درک خوبی از کسب و کار و مسایلی که با آنها روبرو هست، داشته باشیم. بدونیم ورودی های فرآیندهای سازمانی چه هستند و خروجی های مطلوب کدامها هستند. با در دست داشتن چنین اطلاعاتی درک روشنی از سازمان خواهیم داشت.
پس از شناخت کسب و کار و مساله یا مسایلی که باید حل شوند، باید رویکرد تحلیلی Analytical Approach مناسب برای حل مساله را انتخاب کنیم. در اغلب پروژه های دیتاساینس ابتدا ما با Descriptive Analysis شروع میکنیم. پاسخ به سوالاتی از قبیل اینکه چه اشتباهی رخ داده است؟ میتونه جز Descriptive Analysis محسوب بشه. در مرحله بعد Diagnostic Analysis انجام میدهیم. پاسخ به این سوال که چرا این مشکل یا اشتباه رخ داده است جز تحلیلهای تشخیصی محسوب می شود. فاز بعدی باید با استفاده از رویکرد Predictive Analysis به عواقب اینکه اگر این روند ادامه پیدا کند، فکر کنیم. پاسخ به این سوال که چه اتفاقی بعد از این افتاد خواهد افتاد؟ جز اینگونه تحلیلها محسوب میشه. در نهایت با پاسخ به اینکه چه کاری باید انجام دهیم تا مشکل حل شود باید تحلیل تجویزی یا Prescriptive Analytics انجام بدیم.
مشخص کردن الزامات داده ای و روشهای جمع آوری داده
دومین گام در این متدولوژی تشخیص اینه که چه داده هایی رو برای اجرای پروژه دیتا ساینس و حل مشکلی که کسب و کار با اون روبرو هست، نیاز داریم، و چگونه میتونیم جمع آوریشون کنیم؟ مثلا اگر برای یک بانک روی این مساله کار میکنید که چه کسانی میتونن وام دریافت کنن و تا چه سقفی مبلغ وام میتونه باشه باید داده های مشتریان بانک، مثل درآمد ماهانه، شغل و سن و ارزش دارایی هاشون باید جمع آوری بشه. بعد از اینکه مشخص شد چه داده هایی باید جمع آوری بشه و این داده ها از چه نوعی هستند. به این میرسیم که این داده ها چگونه جمع آوری شوند؟ پاسخ به سوالاتی مثل اینکه آیا با استریم دیتا روبرو هستیم یا داده ها در بانکهای اطلاعاتی رابطه ای ذخیره شده اند؟ آیا باید از روشهای Web Scrapping برای جمع آوری داده های متنی استفاده کنیم؟ میتونه به ما کمک بسیاری در این زمینه بکنه. معمولا داده هایی که در این فاز جمع آوری میشوند خام هستند و نیاز به آماده سازی و تمیز کردن دارند.
آشنایی با داده ها و آماده سازی داده
پس از اینکه داده ها جمع آوری شد، باید به شناخت و آماده سازی داده ها بپردازیم در واقع این سومین مرحله در این متدولوژی است. پاسخ به این سوال که آیا با این داده ها میشه مشکل کسب و کار رو حل کرد، چالش اصلی این فاز است. برای پاسخ به این سوال هم باید EDA (Exploratory Data Analysis) انجام داد در واقع EDA اون دسته از تحلیلها هستند که به شناخت بیشتر ما از داده ها کمک میکنن. برای درک روابط بین داده های جمع آوری شده میتونیم از دیتا ویژوالیزیشن و ایجاد یک سری گرافهای ساده هم کمک بگیریم. مثلا استفاده از scatter plot برای نشون داده تاثیر سابقه کار روی حقوق پرسنل سازمان.
وقتی با ماهیت داده های جمع آوری شده آشنا شدیم. میریم سراغ آماده سازی داده ها یا Data Preparation. به عنوان مثال باید فکری برای داده های تکراری یا مفقود شده بکنیم.یا از واحدهای اندازه گیری یکسان در ستونهای مربوط به این نوع داده ها استفاده کنیم، مثلا همه داده های زمانی بر حسب ثانیه، روز یا ماه باشند. یا اینکه اندازه گیری فاصله بر حسب متر باشه نه اینکه یکی بر حسب متر، یکی بر حسب فوت و دیگری بر حسب مایل! گاهی هم لازمه برای حفظ محرمانگی داده ها آونها رو اصطلاحا anonymise یا بی نام کنیم. همچنین در بعضی از مسایل نیاز هست با ادغام داده های چند ستون یک ستون یا ستون های جدیدی ایجاد کنیم که به ما دید بهتری نسبت به داده ها میدن و کمک میکنن تحلیل بهتری از داده ها داشته باشیم. به این کار Feature Engineering میگن که تو بخش ماشین لرنینگ معمولا کاربرد داره و آموزش داده میشه.
ایجاد مدل و ارزیابی آن
گام بعدی ایجاد مدل و ارزیابی اون هست. عموما دو مدل داریم توصیفی و پیش بینی کننده، Descriptive and Predictive Models. مدلهای توصیفی با تحلیل داده هایی که توی دیتابیسها ذخیره شده به دنبال یافتن موضوعات جذاب در گذشته هستند. مثلا چه محصولی در شش ماهه نخست ۲۰۲۱ بیشترین فروش رو داشته. پس این مدلها به ما اطلاعاتی درباره گذشته میدن اما مدلهای پیش بینی کننده همونطور که از اسمشون مشخصه برای اینکه ببینیم چه موقعیت ها و یا چه خطراتی پیش رومون هست، کاربرد دارند. آیا این مشتری خاص میتونه از بازپرداخت وامش بر بیاد یا خیر؟ میتونه یک سوال مناسب باشه که پاسخش از طریق Predictive Models بدست میاد.
بعد از اینکه مدل رو ایجاد کردیم باید میزان دقت اون رو ارزیابی کنیم در واقع باید به این پرسش پاسخ بدیم که آیا این مدل کاری رو که ازش انتظار داریم به درستی انجام میده، و البته به چه میزان؟، که با استفاده از معیارهای مختلفی که برای ارزیابی وجود داره میشه این کار رو انجام داد.
البته با توجه به خروجی ارزیابی یا Evaluation میشه با روشهای بهینه سازی، مدل بهتری رو ایجاد کرد.
توزیع مدل و دریافت بازخورد
گام آخر این متدولوژی هم اینه که مدل رو در اختیار کاربران (Deployment) قرار بدیم تا از اون استفاده کنن و با بازخوردی (Feedback) که به ما میدن سعی کنیم مدل رو بهینه تر کنیم. معمولا یک فرایند Iterative هست یعنی بارها ممکنه بر اساس بازخورد کاربران و احیانا تغییرات جزیی در نیازهاشون مجبور بشیم مدل رو بهبود بدیم و یا اساسا تغییرش بدیم.
امیدوارم که از مطالعه این مطلب لذت برده باشید. خوشحال میشم اگر از نظراتتون در بخش کامنت مطلع بشم.
